
LEO SatCom: Why “Ping Length” Explains Nothing? How Latency in Satellite Networks Actually Works?
Latency in LEO satellite networks is not random — it has rhythm and causality. Why ping is misleading, and how satellite internet latency should actually be understood.


Over the past few years, low Earth orbit (LEO) satellite networks — Starlink, OneWeb, Amazon LEO, and others — have ceased to be a technological curiosity. They are increasingly used in real-world scenarios: as primary or backup connectivity, as communication channels for mobile assets, as infrastructure for drones, logistics, or remote regions. And almost always, the conversation starts with a simple question:
“What’s the ping like?”
“I’ve got 40 ms ping,” “mine is 80,” “here it dropped to 150.”
It sounds familiar — and this is exactly where understanding usually begins to break down.
This article draws on several recent studies focused on real-world measurements and latency control in LEO SatCom networks:
Statistical Characterization and Prediction of E2E Latency over LEO Satellite Networks
Proactive Latency Control: Robust Dual-Loop Adaptation for Predictably Uncertain LEO Networks
These papers are quite technical and primarily of interest to networking and IT professionals. What matters here is something else: explaining why the familiar “just measure ping” approach is misleading in LEO environments, and what actually lies behind the latency figures we observe.
Paths of Space Traffic
Before discussing latency, it is important to understand how traffic actually flows through a LEO network. Unlike terrestrial internet, where routing is usually relatively stable, satellite systems are dynamic at the physical level itself.
A packet travels from the user device to the satellite terminal, then over a radio link to the satellite. From there, it may be forwarded via inter-satellite links, or immediately downlinked to a ground station operated by the provider. Only after that does it enter the conventional IP network and proceed toward the destination server. The return path may be different — it is not necessarily symmetric.
At this stage alone, it becomes clear that latency is not just “signal flight time.” It consists of multiple components: radio propagation, processing at the terminal and satellite, queuing in the space segment, gateway processing, and routing in the terrestrial network. A separate and critical role is played by regular handovers, which are unavoidable due to satellite motion.
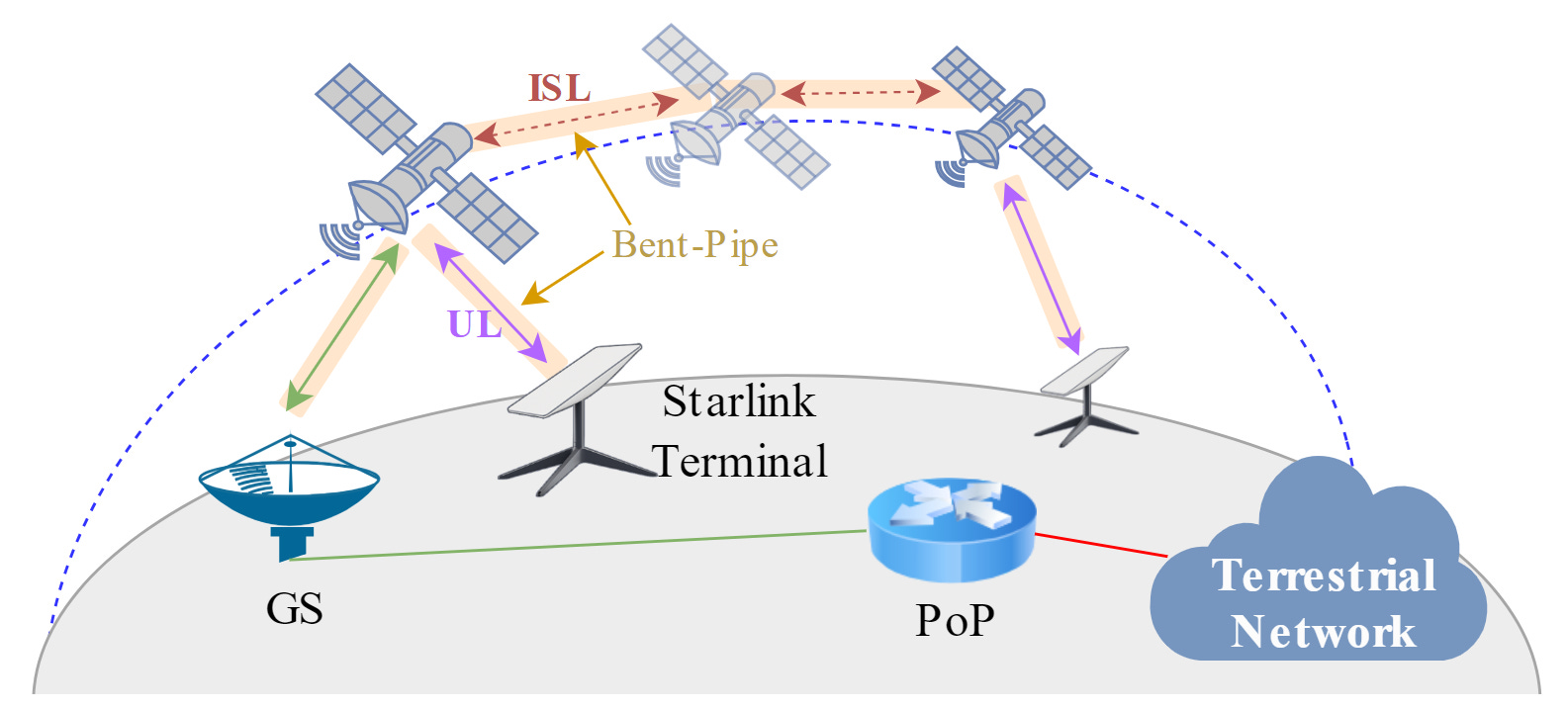
This is why the simplified notion “the satellite is far away, so ping must be high” does not hold. Often, the dominant contribution to latency comes not from distance, but from system dynamics.
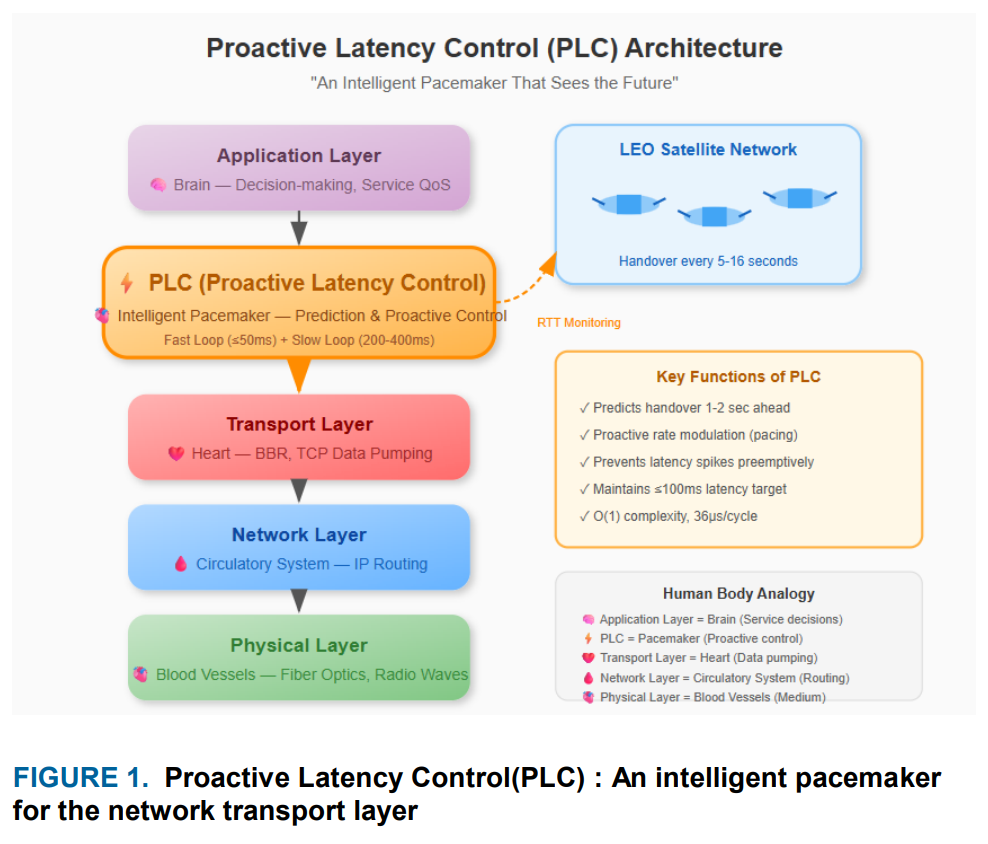
Why Ping Is Not About Real Latency
In the classic internet, ping is a crude but useful indicator. It reflects path congestion and routing issues. In LEO networks, this tool starts lying — not because it is wrong, but because it is far too simplistic.
First, round-trip time hides asymmetry. Uplink and downlink in satellite networks behave differently: queuing, processing, and even routing paths can differ significantly. A single RTT value collapses all of this into an average, stripping away critical information.
Second, a single ping — or even an averaged value — says nothing about the temporal structure of latency. And in LEO systems, temporal structure is precisely what matters most.
Rhythmic Latency Spikes Are Not a Bug — They’re a Feature
When latency is measured at high frequency, something unexpected emerges: LEO networks have rhythm. Latency rises and falls not chaotically, but with near-mechanical regularity.
Approximately every 10–15 seconds, an event occurs related to satellite, beam, or route switching. At that moment, a short but sharp latency spike appears, after which the network quickly returns to a stable state.
For the user, this looks like “sudden lag.”
For the system, it is a deterministic consequence of orbital mechanics. Satellites move — this cannot be avoided. What matters is that these events repeat with high regularity.
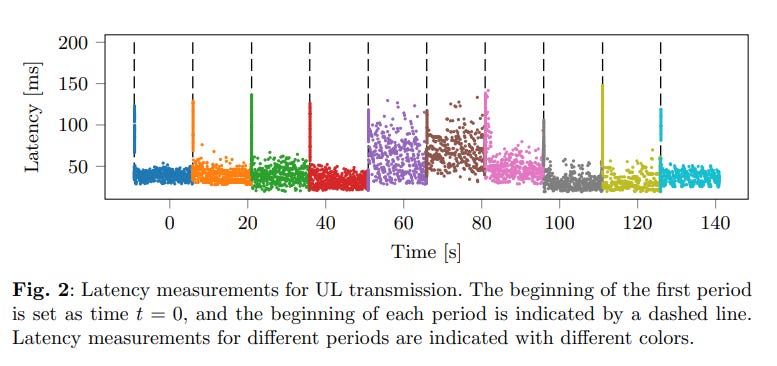
This means that average ping or random measurements miss the most important thing: which phase of the cycle you are currently in.
At this point, latency stops being merely a problem and starts acting as a signal. A slight increase in RTT or one-way delay is often a precursor to an upcoming handover. In effect, the network is “warning” that a brief degradation period is imminent.
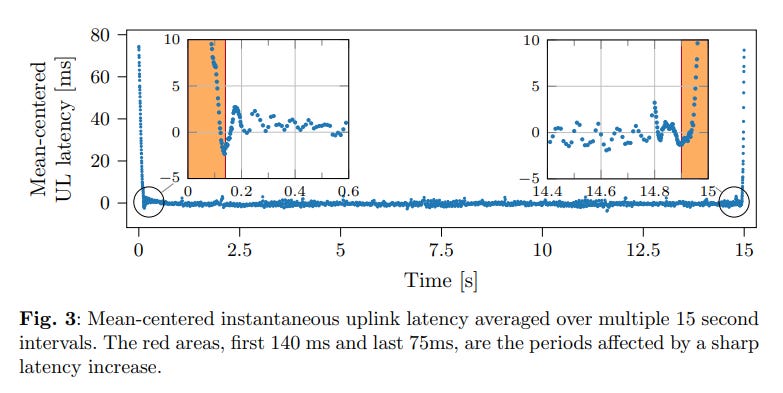
Practice shows that observing latency for just a few hundred milliseconds is often sufficient to predict, with high probability, whether the upcoming interval will be suitable for latency-sensitive traffic or not. For control systems, drones, telemetry, or critical services, this is fundamental: it enables not just reactive behavior, but proactive decision-making.
However, this is also where mistakes are easy to make.
How Intervention Attempts Can Cause Harm
Predicting a bad moment does not automatically mean it is safe to intervene. Modern transport protocols are not static. They operate in phases: aggressive startup, bandwidth probing, stabilization. At certain moments, rising latency is normal — and even necessary — for them.
If rigid, latency-only control is imposed on top of these mechanisms, a conflict emerges. The base algorithm is trying to “accelerate,” while the overlay control is braking. As a result, the system can enter a pathological mode where latency is no longer characterized by short spikes, but by multi-second collapses.
This is one reason why LEO SatCom does not tolerate universal, one-size-fits-all solutions. It is not enough to know what will happen next — it is equally important to understand the current state of the entire system.
Engineers should internalize another critical point: not all latency is equally dangerous in LEO networks. Short, regular spikes tied to handovers are often less harmful than rare but long queues caused by poor traffic control. From a practical standpoint, this means that treating every latency increase as an “error” may be counterproductive.
It is far more important to distinguish physically inevitable events from pathological regimes that the system creates on its own.
Another non-obvious conclusion is that uplink is more critical in LEO networks than RTT measurements suggest. Uplink typically forms the latency tails and determines whether a brief handover turns into a noticeable application-level problem. Systems that make decisions based solely on round-trip metrics risk missing the moment when one direction has already degraded, while the average still appears “normal.”
Starlink: IPv4 over IPv6
A separate but important layer is the IP stack. In the case of Starlink, it is essential to understand that IPv6 is the native and foundational network standard. Core routing, addressing, and traffic management are built on IPv6.
IPv4 is not a first-class citizen in this architecture. It operates on top of IPv6 via encapsulation and address translation mechanisms, including carrier-grade NAT (CGNAT). This means that IPv4 traffic undergoes additional processing stages, may enter different queues, and experiences a different latency and jitter profile.
From the user’s perspective, this can look like “IPv4 is slower or less stable,” but in reality, it reflects different internal processing paths within the same system. Comparing IPv4 and IPv6 pings without this context is yet another way to reach incorrect conclusions.
Conclusion
All of this has practical significance far beyond network engineering. LEO SatCom is increasingly used where peak throughput is less important than controllability and predictability: unmanned systems, logistics, emergency services, and dual-use infrastructure.
In such scenarios, predictable instability is far more valuable than the illusion of stability. It is better to know that every 15 seconds there will be a brief dip than to encounter a rare but uncontrollable multi-second delay.
Both referenced studies also encourage rethinking what a “good channel” means in LEO. Optimizing average latency or maximum throughput makes little sense here. A much more important characteristic is temporal usefulness: what fraction of time intervals is suitable for sensitive traffic, and how predictably the system transitions between “good” and “bad” states. For many applied systems, this is more valuable than formally better averages.
LEO networks force us to rethink the very nature of the internet. Here, latency does not simply mean “bad” — it is a source of information. Here, ping is not truth, but a crude and simplified shadow of a complex process. And here, stability is achieved not by eliminating fluctuations, but by learning to read their rhythm and act at the right moment.
Separately, it is worth noting that LEO networks integrate poorly with universal “one-solution-fits-all” approaches. Algorithms and configurations that work beautifully in terrestrial networks may behave unpredictably in environments with regular but harsh physical-layer events. This means LEO requires dedicated profiles, dedicated testing, and dedicated thinking — not blind reuse of existing practices.
Perhaps the main lesson of LEO SatCom is not about how fast packets can traverse space, but about learning to understand time in networks that are constantly in motion.
The support of paid subscribers of SkyLinker.io will allow us to share even better and even more independent analytics, interesting reviews, and produce training and educational materials. From an inexpensive subscription costing a few cups of coffee per month to a more significant “Patron” level — all of this is clearly and qualitatively converted into information and knowledge, primarily for the defenders of Ukraine.
All the most interesting things from the world of communication and space technologies are also available in the form of educational audio podcasts and video lectures both on the website and on the SkyLinker Youtube channel.